
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Kernel
- rootfs
- kernel image
- kernel img
- liblzma
- cwe-506
- 백도어
- newbie
- CVE-2024-3094
- kernel build
- xz-utils
- Today
- Total
ZZoMb1E
[KERNEL] Slab Allocator 본문
※ 자료들을 참고하여 분석을 진행하였기에 잘못된 부분이 있을지도 모릅니다.
※ 보완 혹은 수정해야 되는 부분이 있다면 알려주시면 확인 후 조치하도록 하겠습니다.
※ 이미지의 경우 제가 참고한 레퍼런스의 이미지가 설명이 잘되어 있어서 가져왔습니다.(링크 가장 하단에 있습니다.)
User 영역에서 malloc, free 등의 함수에 의한 메모리 할당은 ptmalloc에서 관리를 수행한다.
Kernel 영엑에서도 User 영역의 ptmalloc 처럼 메모리를 효율적으로 관리하기 위한 Allocator가 필요로 하는데 이게 바로 Slab Allocator이다.
Slab Allocator는 Slab Allocator, Slub Allocator, Slob Allocator 이렇게 3가지가 존재한다.
Slab Allocator
- 매우 복잡한 처리 과정으로 인해 효율이 떨어짐
- user space [ fastbin, unsorted bin etc ] ↔ kernel space [full list, partial list, empty list ]
- 관리되는 주체 : slab
- slab 객체에는 메타데이터 정보 포함
- 관리 과정에서 overhead가 다수 발생
Slub Allocaotr
- 현재 기본적으로 사용되는 Allocator
- partial list 만을 활용하여 관리
- slab에 비해 메모리 지역성 향상 → 메모리 단편화 줄어듬
- slab 객체를 최적화 한 구조 → slub 객체
Slob Allocaotr
- 주로 적은 용량을 가지는 임베디드 리눅스 환경에서 사용되는 Allocator
- 속도는 느리지만 메모리 소모가 적음
앞서 말했듯이 Slab Allocator는 메모리의 효율적인 관리를 위해서 등장했다.
이게 어떤 과정을 거치기 때문에 이전보다 효율적으로 관리를 할 수 있는지를 간단하게 살펴보도록 하겠다.

page 단위가 4K라고 가정을 하고, 여기에 128 byte 크기의 메모리를 할당 요청을 하는 상황을 살펴보도록 하겠다.
만약 Slab Allocator가 없다고 한다면 4K 크기인 page 하나를 128 byte를 위해서 사용하게 된다.

이는 매우 비효율적으로 메모리 자원을 사용할 뿐만 아니라 내부 단편화 문제까지 발생하게 된다.
- 내부 단편화
- 메모리 할당 요청에 의해 메모리 공간이 할당 되었지만, 할당된 공간에 비해 사용되는 메모리 공간이 작아 사용하지 않는 공간이 남아 있는 경우를 [내부 단편화]라고 한다.
- 이는 실제로 사용 가능한 메모리 공간이 줄어드게 된다.
이를 해결하기 위해 나온 기술이 Slab Allocator이다.

Slab Allocator는 4K의 공간을 할당을 할 때, 전 처럼 하나의 메모리에 하나의 공간이 아닌 하나의 공간을 쪼개어 요청 들어온 메모리를 할당한다. 이는 Kernel의 Buddy System과 유사하다.
※ Buddy System은 기본적으로 외부 단편화 문제를 해결하기 위해 사용되지만, Buddy System에 Slab Allocator가 포함되어 있는 구조이다. [별도의 개념이 아니다]
메모리 관리에 대한 간단한 흐름을 살펴보기 위해서는 2가지 개념이 필요로 하다.
- Slab Cache
- Kernel에서 자주 사용되는 구조체에 대한 동적 메모리를 사전에 확보하고 관리하는 주체
- Slab Object
- 사전에 정의된 패턴에 대한 요청을 처리
- 할당 및 해제되는 과정에서는 바로 반환이 아닌 일시적인 대기를 수행
- 재할당 및 유사 크기에 대한 메모리 할당 요청을 대비
여기서 자주 사용되는 패턴 / 구조체가 언급이 되었는데, 가장 대표적인 것으로 살펴보도록 하겠다.
프로세스가 생성되어 돌아갈 때는 pcb 정보를 담기 위해 struct task_struct 형태의 구조체가 사용되게 된다.
이때 프로세스를 반복적인 실행을 하게 되면, 실행할 때마다 해당 구조체를 메모리에 요청하고 받아와야 하기 때문에 Overhead가 발생하게 된다. 이를 위해 사전에 자주 사용하는 패턴을 위한 메모리 공간을 할당하고 요청이 들어오면 제공하는 방식을 사용한다.

이 패턴의 경우 /proc/slabinfo를 살펴보면 확인할 수 있다.
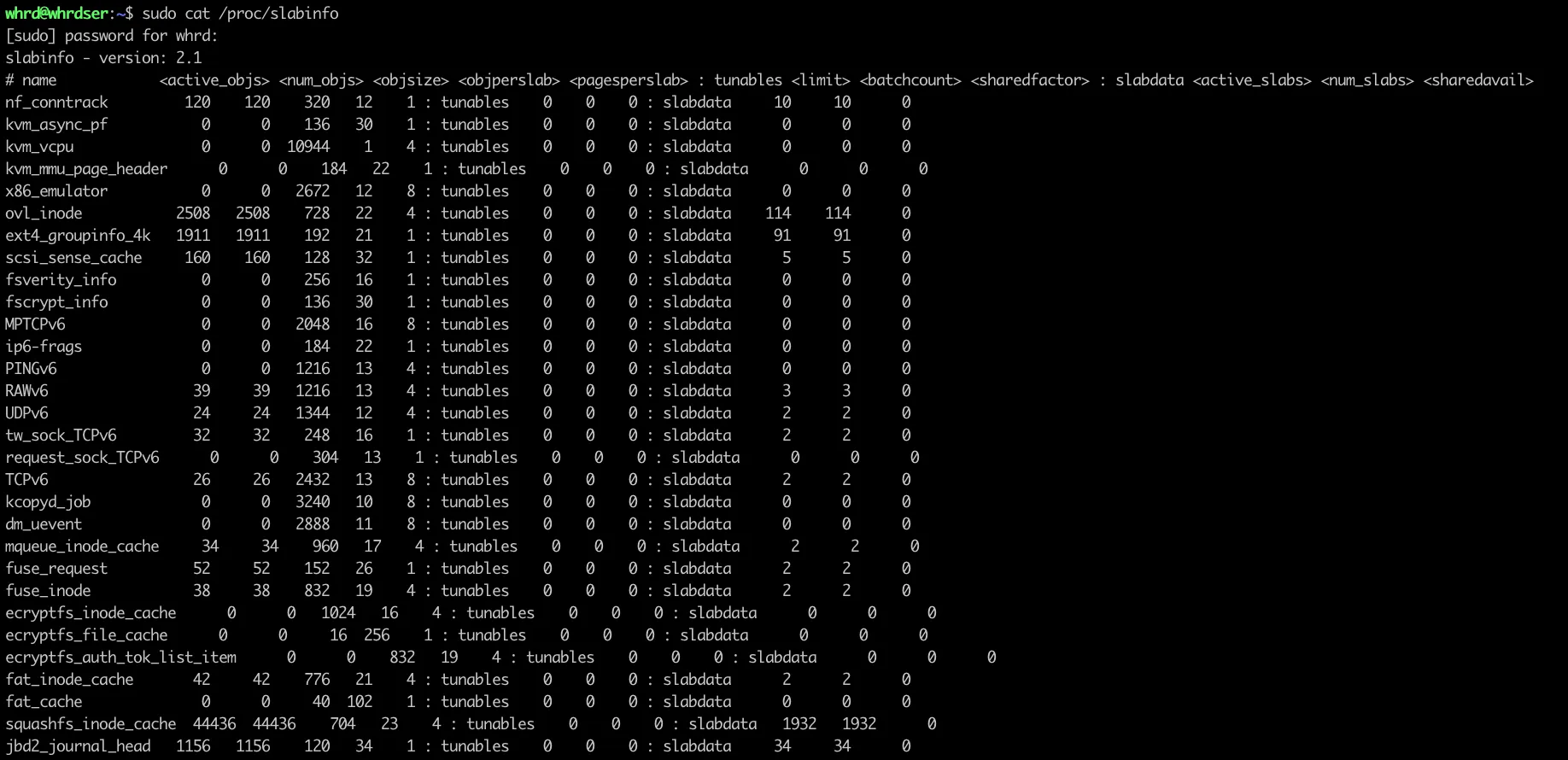
앞에서 언급했던 struct task_struct 역시 존재하는 것을 확인할 수 있다.

이제 간단한 흐름을 살펴보겠다.

구조는 위 그림과 같이 구성되어 있다.
- 같은 크기의 Slab Object들이 모여서 Slab Page를 구성
- 서로 다른 크기의 Slab Page들이 모여 Slab Cache를 구성

정확한 구조를 보여주기 위해 하나의 그림을 가져왔다.
Cache 같은 경우 cpu와 node 별로 2가지 방식으로 관리가 되고 있다.
- node
- node 별로 메모리 접근 속도가 다르기 때문에 page를 node 별로 관리
- cpu
- 빠른 메모리 할당을 위해 cpu 별로 나눠서 관리
- 할당/해제에 관련된 page가 지정 및 partial 리스트에서 관리됨
node와 cpu로 구분한다고 했지만 별도로 관리하는 것이 아닌 서로 상호작용을 하면서 메모리를 효율적으로 관리한다.
이는 뒤에서 다룰 메모리 할당 및 해제를 보면 확인할 수 있다.

Freelist
per-cpu의 page에서 free object의 시작 부분을 의미한다.
이때 free object는 다음 free object를 가리키는 단일 연결 리스트 형태를 가지고 있다.
이 freelist를 어떻게 관리하고 사용하는지에 따라서 Slab Allocator의 효율성이 영향을 받는다.
struct page
{
...
struct
{ /* slab, slob and slub */
union
{
struct list_head slab_list;
struct
{ /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union
{
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct
{ /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1; // 뒤에서 설명함
};
};
};
...이 코드를 살펴보면 freelist가 page에서도 따로 관리하는 것을 살펴볼 수 있다.
- cpu->freelist
- 현재의 CPU가 직접 관리
- Object의 할당 및 해제가 가능
- cpu->page->freelist
- 현재 CPU가 아닌 다른 CPU가 현재 CPU가 관리하는 Object를 해제했을 때 관리
- 자기 자신의 CPU가 아닌 Object는 해제만 가능 / 할당은 불가
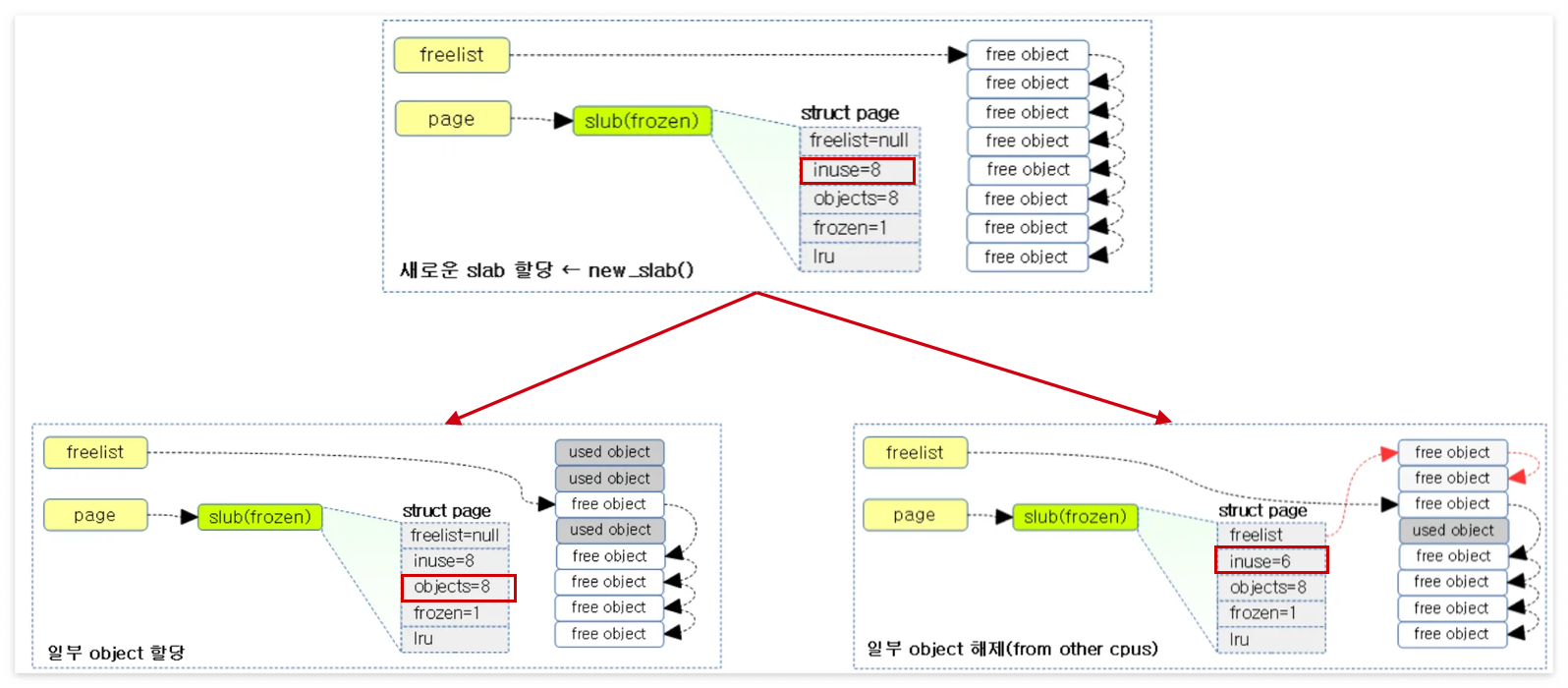
위 그림을 보면 알 수 있듯이 현재의 CPU에서 해제를 했을 경우 page의 inuse 값이 8로 유지되는데, 다른 CPU에 의해서 해제되었을 경우 cpu->freelist에서 관리하는 것이 아니게 되고 cpu->page->freelist에서 관리하는 것이 되기 때문에 2개가 줄어 inuse가 6개인 것을 볼 수 있다.
메모리 할당 방식에는 크게 5가지로 이루어져 있다.
fastpath
- 가장 빠른 할당 방식
- cpu->freelist에 할당 가능한 object가 있으면 바로 할당하는 방식
- 이때 cpu->freelist에는 page가 아닌 object가 연결됨

Slowpath-1
- cpu->freelist에 사용할 수 있는 object가 없을 경우 실행
- cpu->page->freelist에 들어있는 object들을 cpu->freelist로 올린 다음 fastpath 수행
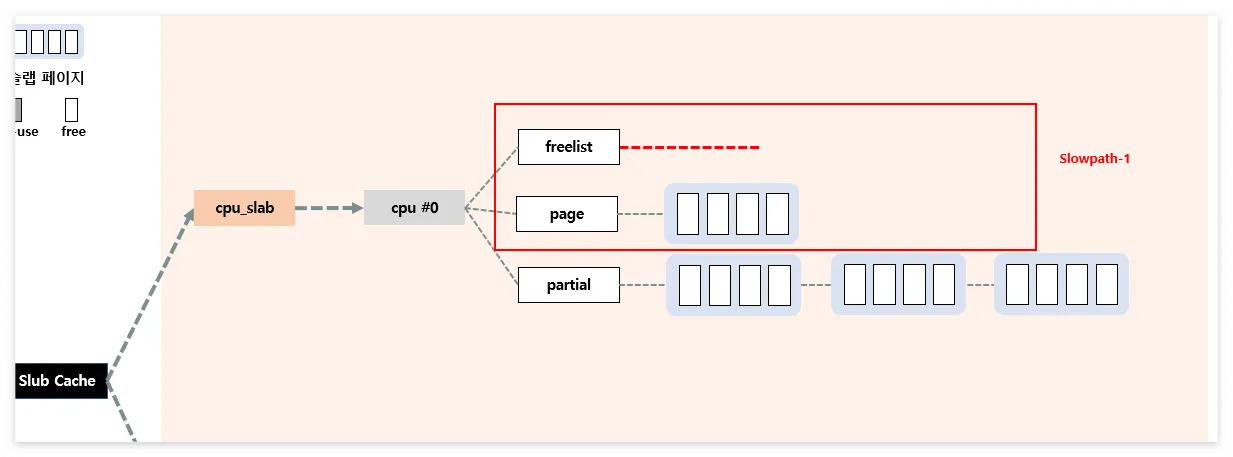

Slowpath-2
- cpu->page->freelist에도 object가 없는 경우 (fastpath, slowpath-1을 사용할 수 없는 상황)
- cpu->partial page를 활용
- cpu-> partial->page를 cpu->page로 이동
- 옮겨진 object들을 cpu->freelist로 이동
- 이후 fastpath 수행
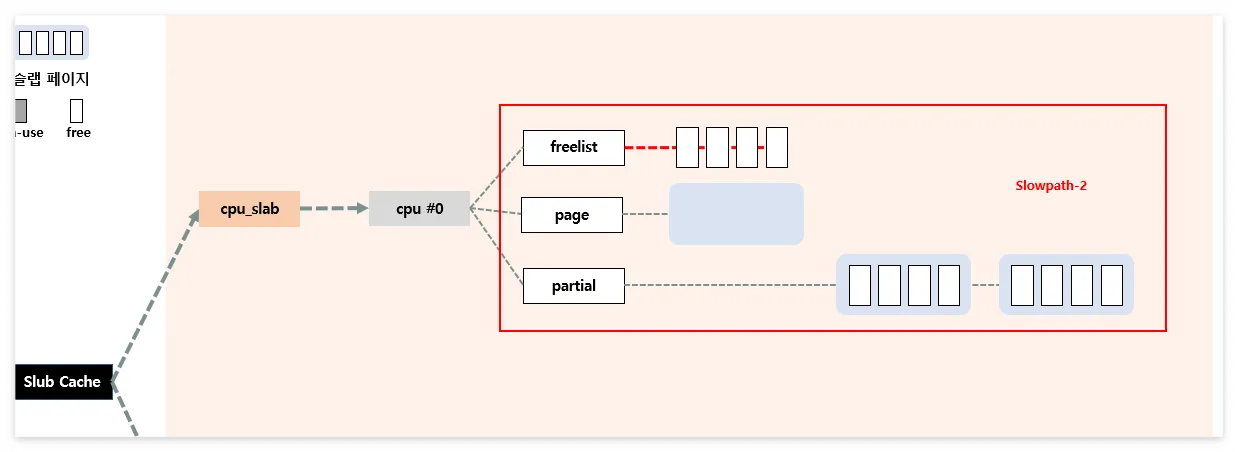
Slowpath-3
- cpu->partial에도 할당 가능한 object가 없는 경우 (fastpath, slowpath-1, slowpath-2을 사용할 수 없는 상황)
per-node 활용
- node->partial에 있는 첫 page를 cpu->page로 이동
- object들은 cpu->freelist로 이동
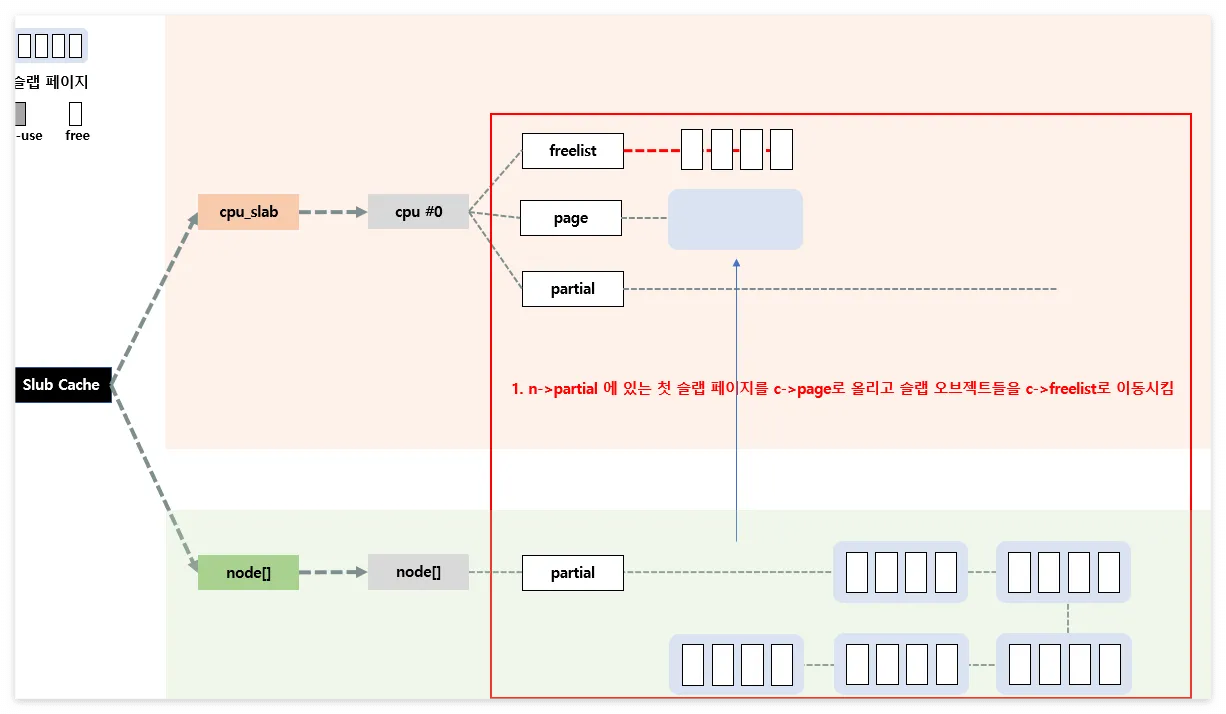
- node->partial에 있는 page의 일부를 cpu->partial로 이동
- 이때 node->partial이 비어있는 경우 per-node의 cache가 아닌 다른 node의 partial를 사용

Slowpath-4
- 앞의 방법들을 모두 사용할 수가 없을 때 사용하는 단계
- Buddy System으로부터 새롭게 page를 할당
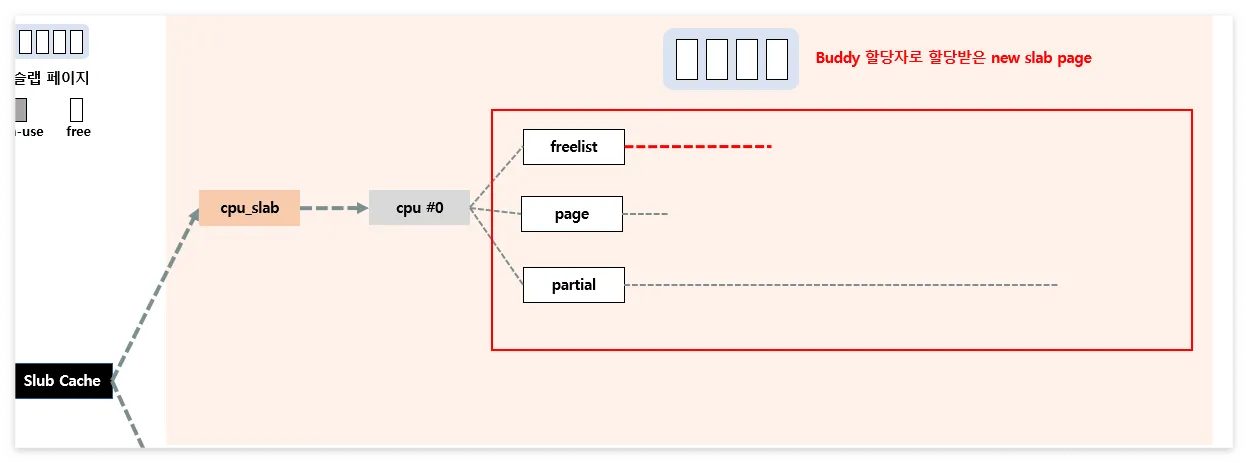
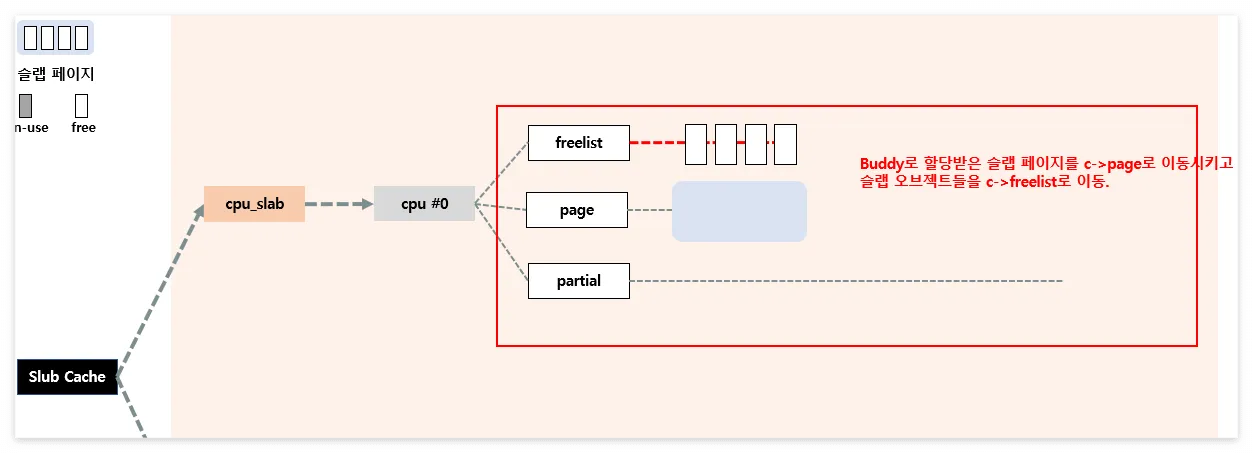
지금까지의 흐름 단계를 그리면 아래의 그림과 같다.

반환의 경우 할당할 때 가져왔던 곳으로 다시 반환하는 구조이다.
5가지 모두에 대해서는 다루지 않고 fastpath만 살펴보겠다.

fastpath의 경우 cpu->freelist에 있는 것을 바로 할당했기 때문에 해당 위치로 그대로 반환하는 구조이다.
Reference
Slab Memory Allocator -1- (구조)
<kernel v5.0> Slab Memory Allocator 슬랩(Slab, Slub, Slob) object는 커널이 사용하는 정규 메모리 할당의 최소 단위이다. 커널은 다음과 같이 3가지 중 하나를 선택하여 빌드되어 사용된다. 서로에 대한 차이
jake.dothome.co.kr
[Linux Kernel] Slab Memory Allocator 란?
목차
jeongzero.oopy.io
'STUDY > KERNEL' 카테고리의 다른 글
| [KERNEL] Heap Use After Free (0) | 2024.11.14 |
|---|---|
| [KERNEL] Heap OverFlow (0) | 2024.11.14 |
| [KERNEL] build (0) | 2024.11.12 |
| [KERNEL] Send Script to CTF (0) | 2024.10.29 |
| [KERNEL] KROP_(KPTI bypass) (0) | 2024.06.28 |


